The birth of the Soviet missile defense system. "El Burroughs"

Burtsev inherited love and respect for Western prototypes from his teacher, yes, in principle, starting from BESM-6, ITMiVT actively exchanged information with the West, mainly with IBM in the USA and the University of Manchester in England (it was this friendship that forced Lebedev, incl. h. to lobby for the interests of the British ICL, and not the German Robotron at that memorable meeting in 1969).
Naturally, "Elbrus" could not have had a prototype, and Burtsev himself admits this openly.
The answer is unequivocal: "Yes." Before starting to design a new computer, we always very carefully studied the developments of the whole world in this area.
At that time, the question arose of raising the level of machine language in order to reduce the gap between the high-level language and the command language in order to increase the efficiency of passing programs written in a high-level language.
In this direction in the world worked in three places.
In theoretical terms, the work of Ailif was the most powerful: “Principles for constructing a basic machine”, at the University of Manchester in the laboratory of Kilburn and Edwards the MU-5 machine (“Manchester University-5”) was created, and at Burrows, machines were developed for banking and military applications .
I was at all three companies, talked with the main developers and had the necessary materials on the principles embodied in these developments.
When designing the Elbrus-1 and Elbrus-2 MVKs, we took from advanced developments everything that seemed worthwhile to us. This is how all new machines are made and should be developed.
The development of the MVK Elbrus-1 and Elbrus-2 was influenced by the architecture of HP, 5E26, BESM-6, and a number of other developments of that time.
At that time, the question arose of raising the level of machine language in order to reduce the gap between the high-level language and the command language in order to increase the efficiency of passing programs written in a high-level language.
In this direction in the world worked in three places.
In theoretical terms, the work of Ailif was the most powerful: “Principles for constructing a basic machine”, at the University of Manchester in the laboratory of Kilburn and Edwards the MU-5 machine (“Manchester University-5”) was created, and at Burrows, machines were developed for banking and military applications .
I was at all three companies, talked with the main developers and had the necessary materials on the principles embodied in these developments.
When designing the Elbrus-1 and Elbrus-2 MVKs, we took from advanced developments everything that seemed worthwhile to us. This is how all new machines are made and should be developed.
The development of the MVK Elbrus-1 and Elbrus-2 was influenced by the architecture of HP, 5E26, BESM-6, and a number of other developments of that time.
So, Burtsev, unlike many, admits that he did not hesitate to generously borrow architectural ideas from his neighbors and even says where to look for tails.
Let's take advantage of the generous offer and dig up three sources and three components of Elbrus.

The first is John Iliffe's monograph Basic Machine Principles (Macdonald & Co; 1st edition, January 1, 1968) and his article Elements of BLM (The Computer Journal, Volume 12, Issue 3, August 1969, Pages 251 –258), the second is a virtually unknown MU5 computer built as an experiment at the University of Manchester, and the third is a Burroughs 700 series.
Isn't it a clone of Burroughs himself?
Let's start to understand in order.
First, some of the readers may have heard the term "von Neumann architecture" often used in the context of boasting: "here we have designed a unique non-von Neumann computer." Naturally, there is nothing unique in this, if only because machines with von Neumann architecture were no longer built back in the 1950s.
After working on the ENIAC (which was programmed in the manner of tabs, with a lot of wires flowing around, and there was no question of any control of the calculations by a program loaded into memory, and there was no question) for the next machine, called the EDSAC, Mauchly and Eckert came up with the main ideas for its design.
They are as follows: a homogeneous memory that stores commands, addresses and data, they differ from each other only in how they are accessed and what effect they cause; the memory is divided into addressable cells, to access it is necessary to calculate the binary address; and finally, the principle of program control - the operation of the machine, is a sequence of operations for loading the contents of cells from memory, manipulating them and unloading them back into memory, under the control of commands that are sequentially loaded from the same memory.
Almost all machines (and there were only a few dozen) produced in the world from 1945 to 1955 obeyed these principles, as they were built by academic scientists who were widely familiar with the First Draft of a Report on the EDVAC, sent to universities by the curator von Neumann by Herman Heine Goldstine on his behalf.
Naturally, this could not go on for long, because the pure von Neumann machine was rather a mathematical abstraction, like a Turing machine. It was useful to use it for scientific purposes, but real computers built in accordance with these ideas turned out to be too slow.
The era of pure von Neumann machines ended back in 1955-1956, when people first began to think about pipelines, speculative execution, data driven architecture and other such tricks.
In the year of von Neumann's death, the MANIAC II computer (Mathematical Analyzer Numerical Integrator and Automatic Computer Model II) was launched at the Los Alamos Scientific Laboratory with 5 lamps, 190 diodes, and 3 transistors.
It ran on 48-bit data and 24-bit instructions, had 4 words of RAM, and had an average speed of 096 KIPS.
The machine was designed by Martin H. Graham, who proposed a fundamentally new idea - to mark data in memory with appropriate tags for greater reliability and ease of programming.
The following year, Graham was invited by the staff of Rice University in Houston, Texas to help them build a computer as powerful as Los Alamos. The R1 Rice Institute Computer project lasted three years, and in 1961 the machine was ready (later it was replaced by the standard IBM 7040 for serious American universities, and, ironically, the Burroughs B5500).
The decoding scheme of 2 instructions per word, as in MANIAC II, seemed to Graham to be too fancy, so R1 operated on 54-bit words with fixed-width instructions for the whole word and had a similar tag architecture. The actual word length was 63 bits, of which 7 were the error correction code and 2 were the tag.
The R1's indirect addressing mechanism was much more advanced than the IBM 709's - in fact, they were almost ready-made descriptors from future Burroughs machines. Graham was also a talented electrical engineer and invented a new type of lamp-diode cell for the R1, called the Single Sided Gate, which made it possible to achieve an excellent frequency of 1 MHz for those years. The machine had 15-bit addresses, 8 data/command registers, and 8 address registers.

The first generation of tagged architectures appeared literally immediately after the death of von Neumann. Ailif and Graham's machines, on the left is a part of the MANIAC II processor, on the right - Ailif himself is involved in the installation of the main rack R1. Photo https://www.sciencephoto.com and https://scholarship.rice.edu
Rice University for the USA is something like the Soviet MINEP, so it is not surprising that the creation of a computer (which was going to be used to study the hydrodynamics of oil) was partially funded by the Shell Oil Company.
Her curator was Bob Barton (Robert Stanley Barton), a talented electronics engineer. In 1958 he took a course in mathematical logic and Polish notation applied to algebra and went to work for Burroughs, in 1961 building the legendary B5000 based on the stack tag architecture.
The same Briton Ilif worked on the R1 software. His team created the SPIREL operating system, the AP1 symbolic assembler, and the GENIE language, which became one of the forerunners of OOP. The OS had an incredibly advanced dynamic memory allocation mechanism and a garbage collector, as well as data and code protection mechanisms.
For his operating system, Ailif developed a new array addressing mechanism using a vector of pointers to data vectors. This idea was so advanced over Fortran-style addressing (the address contains a step and offset for each element of the array) that it was named after the creator, and since then the Ailif vectors have been used everywhere, from Ferranti Atlas to Java, Python, Ruby, Visual Basic .NET, Perl, PHP, JavaScript, Objective-C and Swift.
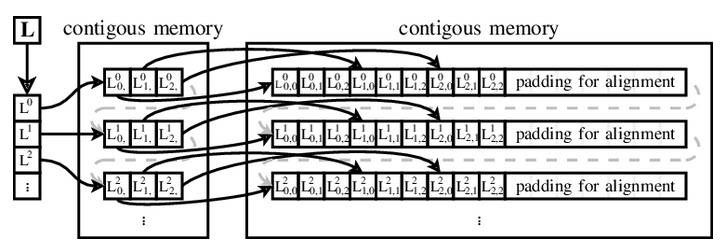
Using the Ailif vector to address a 3x3 matrix (https://www.researchgate.net)
In the late 1950s, von Neumann's theoretical model of the machine faced a challenge to which it did not have an adequate answer (and therefore died completely).
Computers became fast enough that only one person could not load them with work - the concept of a classic mainframe with terminal access and a multitasking operating system appeared.
We will not delve into the complexities that await architects on the way to multitasking (any sensible textbook on the design of operating systems will do for this), we only note that code reentrancy is critical for its implementation, that is, the ability to run several instances of the same program at the same time, working over different data, so that the data of one user is protected from changes by another user.
Leaving all these problems entirely on the heads of the OS architect and system programmers seemed not a very good idea - the complexity of software development would have increased too much (remember how the OS / 360 project ended in a fabulous failure, Multics also did not take off).
There was also an alternative way out - to create a suitable architecture for the computer itself.
It was these possibilities that were considered almost simultaneously by colleagues in R1 - the practitioner Barton, who designed the B5000, and the theorist Ailif, who wrote the very Basic Machine Principles that inspired Burtsev so much.
ICL (with which we never teamed up) led the development of advanced architectures from 1963 to 1968 (it was on the basis of the work that the article was written), Ilif built a BLM prototype for them with hardware memory management methods even more advanced than in Burroughs machines .
Ailif's main idea was an attempt to avoid the standard for other systems (and in those years, slow and inefficient) memory sharing mechanism based purely on software methods - context switching (a term of the OS architecture, meaning, in a simple way, temporary unloading and saving one running process and loading and starting execution of another) by the operating system itself. From his point of view, the hardware approach using descriptors was much more efficient.
The BLM project was closed in 1969, but its developments were partially used in the advanced ICL 2900 Series mainframe line, released in 1974 (which we could well have developed jointly, but, alas).
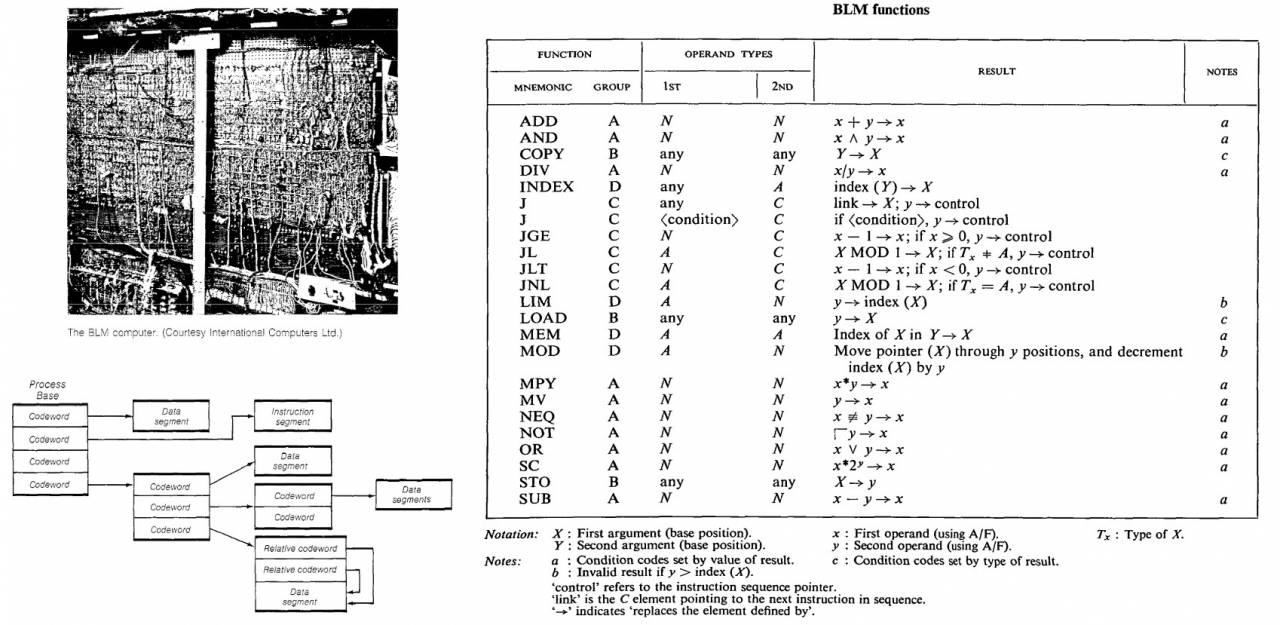
The second generation of already tag-descriptor machines, unfortunately, only this photo from the book Descriptor-Based Computer Systems (Levy, Henry M. 1984) remained from BLM. The command system is reproduced from Ailif's original article (so that readers can immerse themselves in the problem in the wake of Burtsev).
Naturally, the problem of effective memory protection (and hence time sharing) was a concern in the 1960s for almost all computer scientists and corporations.
The University of Manchester did not stand aside and built its fifth computer, called MU5.
The machine was developed in collaboration with the same ICL since 1966, the computer was supposed to be 20 times faster than Ferranti Atlas in performance. Development continued from 1969 to 1974.
MU5 was controlled by the MUSS operating system and included three processors - the MU5 itself, the ICL 1905E and the PDP-11. All the most advanced elements were available: tag-descriptor architecture, associative memory, instruction prefetching, in general - it was the pinnacle of technology of those years.
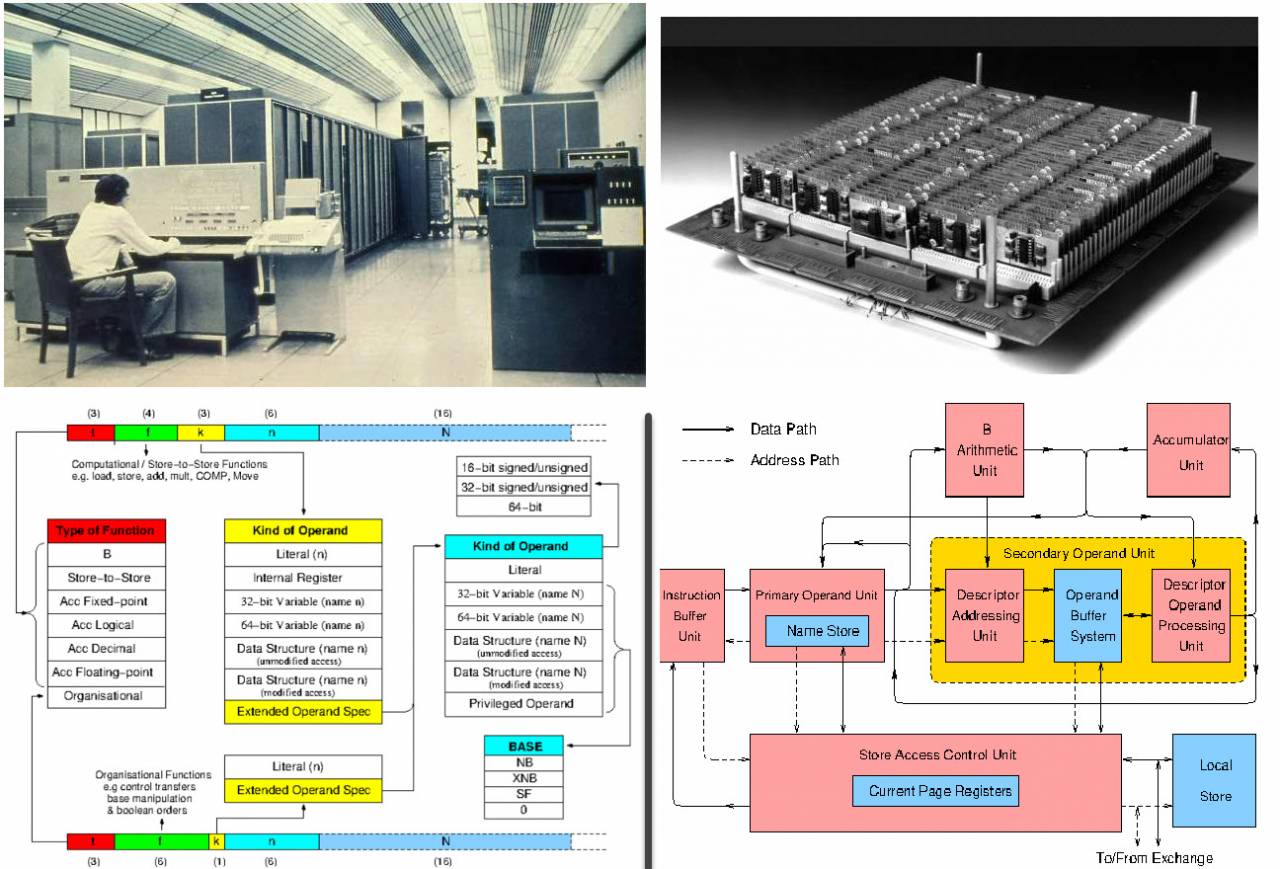
Manchester Machine 5 - the only photo, excellent description of the command system and architecture (https://ethw.org)
MU5 served as the basis for the ICL 2900 Series and worked at the university until 1982.
The last Manchester computer was the MU6, which consisted of three machines: the MU66P, an advanced microprocessor implementation used as a PC; MU66G is a powerful scalar scientific supercomputer and MU66V is a vector-parallel system.
Scientists have not mastered the development of microprocessor architecture, MU66G was created and worked at the department from 1982 to 1987, and for MU66V a prototype was built on Motorola 68k with vector operations emulation.

The ICL 2900 Series was one of the few original machines that competed quite vigorously against the S/360. For British users of the 1980s, this series is full of warmth and nostalgia, as for the Soviet BESM-6. Photo http://www.tavi.co.uk and http://www.computinghistory.org.uk
The further progress of descriptor machines was to be the so-called scheme. capability-based addressing (literally, “addressing based on capabilities”, does not have a well-established translation into Russian, since the domestic school was unfamiliar with such machines, in the translation of the book “Modern Computer Architecture: in 2 books” (Myers G. J. , 1985) it is very aptly named potential addressing).
The meaning of potential addressing is that pointers are replaced by special protected objects that can be created only with the help of privileged instructions executed only by a special privileged process of the OS kernel. This allows the kernel to control which processes can access which objects in memory without having to use separate address spaces at all, and therefore without the overhead of a context switch.
As an indirect effect, such a scheme leads to a homogeneous or flat memory model - henceforth (from the point of view of even a low-level driver programmer!) There is no interface difference between an object in RAM or on disk, access is absolutely uniform, by calling a protected object. The list of objects can be stored in a special memory segment (as, for example, in the Plessey System 250, created in 1969-1972 and representing the embodiment in hardware of a very esoteric computational model called λ-calculus) or encoded with a special bit, as in the prototype IBM System /38.
The Plessey System 250 was developed for the military, and as the central machine of the Department of Defense communications network was successfully used during the Gulf War.
This computer was the absolute pinnacle of network security, a machine in which there were no superusers with unlimited privileges as a class, and no way to elevate one's privileges through hacking to do what should not be done.
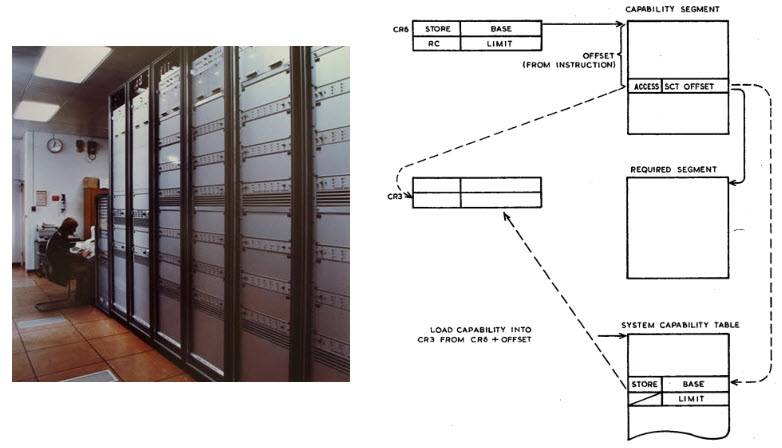
Plessly 250 the only known photo (from the collection of Kenneth J Hamer-Hodges) and a diagram of the operation of potential addressing from the monograph Capability Concept Mechanisms And Structure In System 250, DM England, 1974.
Such an architecture was considered incredibly progressive and advanced in the 1970s-1980s and was developed by many firms and research groups, the CAP computer machines (Cambridge, 1970-1977), Flex Computer System (Royal Signals and Radar Establishment, 1970s), Three Rivers PERQ (Carnegie Mellon University and ICL, 1980-1985) and most famously the failed Intel iAPX 432 microprocessor (1981).
It's funny that the initiators of 90% of all the most original and strange architectural solutions in the 1960s and 1970s were the British (in the 1980s - the Japanese, with a similar result), and not the Americans.
British scientists (yes, those very ones!) tried their best to stay on the crest of the wave and confirm their qualifications as outstanding computer science theorists. The only pity is that, as in the case of the Soviet academic development of computers, all these projects were phenomenal only on paper.
ICL desperately tried to enter the world's top manufacturers of advanced iron, but, alas, it did not work out.
The Americans at first thought that the Anglo-Saxon colleagues, given their pioneering contribution to IT since the time of Turing, would not give bad advice, and were badly burned twice - and the Intel iAPX 432 and IBM System / 38 failed miserably, which caused a great turn of the mid-1980s towards modern processor architectures (it was just then that the American school of computer engineering discovered the principle of RISC machines, which turned out to be so successful from all sides that 99% of modern computers are somehow built according to these patterns).

The CAP computer is still in the Cambridge laboratory, the IBM System / 38 prototype and the Three Rivers PERQ workstation (photo https://en.wikipedia.org and https://www.chiark.greenend.org.uk)
Sometimes it’s even interesting - what developments would a fully-fledged Soviet-British school have rolled out by the 1980s with their advanced production culture, our common crazy ideas and the ability of the USSR to inject billions of petrodollars into development?
It is unfortunate that these opportunities closed forever.
Naturally, information about all the advanced developments of the British came to Burtsev literally from first hand and day after day, given that ITMiVT had excellent contacts with the University of Manchester (since the early 1960s and work on BESM-6), and with firm ICL, with which Lebedev so wanted to make an alliance. However, Burroughs was the only commercial implementation of tag descriptor machines.
What can be said about Burtsev's work with this machine?
The Incredible Adventures of Burroughs in Russia
Soviet computing was an extremely closed area, for many machines there are no photographs, sensible descriptions (about the architecture of the Kitovskaya M-100, for example, nothing is really known until now), and in general surprises await at every step (like the discovery in the 2010s Computer "Volga", the existence of which was not even suspected by Revich, Malinovsky and Malashevich, who took dozens of interviews and wrote books based on them).
But in one particular area there were more silences and secrets than even in military vehicles. These are references to American computers that worked in the Union.
This topic was so disliked to be raised that one might get the impression that, apart from the well-known CDC 6500 in Dubna, there were no American computers in the USSR as a class at all.
Even information about CYBER 170 and 172 had to be mined bit by bit (and there were HP 3000s that were in the USSR Academy of Sciences and a bunch of others!), but the presence of a real live Burroughs in the Union was considered by many to be a myth.
Not a single Russian-language source, interview, forum, book contains even a line dedicated to the fate of these machines in the USSR. However, as always, our Western friends know much more about us than we do ourselves.
As a result of careful searches, it was established that Burroughs was dearly loved in the Social Block and used with might and main, although domestic sources here got water in their mouths.
Fortunately, there are enough fans of this architecture in the USA who know everything about it, including the full number of installations of each model of their mainframes, down to serial numbers. They summarized this information in a table, which they generously shared, and the document also includes the sources of information for each shipment of Burroughs computers to the Warsaw Pact countries.
So, let's turn to the book Economic Statecraft during the Cold War: Eurpoean Responses to the US Trade embargo, which reveals to us the secrets of Soviet procurement.
Early in October 1969 an administration interagency staff study group… By this time US computer corporations commenced selling in East Europe. The Burroughs Corporation of Detroit installed four of their large B5500 computers in Czechoslovakia and one in Moscow that were equal to the mid-range of IBM's computers. Soviet programmers and maintenance staff were trained at the Detroit Plant.
Oh, how, by 1969, Burroughs B5500 was not only installed in Moscow, but Soviet specialists also managed to undergo an internship at the company's factory in Detroit!
Another 4 cars were sold to Czechoslovakia on a government order, unfortunately, it is not known where they were installed and what they did, but obviously not at universities, the column “user” in the table indicates “government”. The most powerful B6700 (later upgraded to B7700!) Was sold in the GDR and used at the University of Karlsruhe.
Further attempts to clarify information about deliveries to Moscow forced us to contact the Southwest Museum of Engineering, Communications and Computation (Arizona, USA).
On their website, you can find a footnote to a 1982 article by Alistair Mayer of ACM's Computer Architecture News (Alastair JW Mayer, The Architecture of the Burroughs B5000 – 20 Years Later and Still Ahead of the Times), a letter from engineer Rea Williams ) from the Burroughs Corporation installation and support team:
Well way back when, I do not remember the exact year, around 1973 … Burroughs sold a B6500 (B6700) to the Oil Ministry of Russia. It was a very special system with Cyrillic printers, special paper tape readers and some other very special stuff. This was during the cold war, but we (Burroughs) had some special permission to supply the system. I participated in the "ride out" system at the City of Industry plant. Glen was with our TIO organization and went to Russia to help install and train the local people to maintain it. He told stories of the GRU or whatever distrusting their card games because they thought the Burroughs guys were "collaborating" or something and they had to leave their room doors open. Great stories, wish I could remember them all. So, at the end he gave me the pin. I have some other stuff around that I will tell you about as well, later.
By the way, in honor of such an event, the Soviets issued commemorative badges with the Burroughs emblem and the inscription "Barrows" and distributed them to the project participants. Williams' original badge adorns the title of this article.
So, the Soviet oil industry (generally parallel to all the lawlessness that was going on around our military and scientific computers), being extremely influential, rich and infinitely far from all the showdowns of the Academy and the party, not wanting to be content with domestic computers (and absolutely not wanting something there, to order from someone from the Soviet research institutes and wait until after ten years of showdowns they all fail), calmly took it and bought herself the best that she could - an excellent B6700. They even called in an installation team from within the corporation to get the precious machine working properly.
It is not surprising that this episode, which clearly shows how really serious people (let's not forget that the oil workers brought the country most of the money, which the military and academics then spent on their games) treated domestic cars, they tried to forget stronger.

Burroughs B6700 of the University of Tasmania and the latest in the line of Burroughs Large Systems - the great B7900 (http://www.retrocomputingtasmania.com, https://pretty-little-fools.tumblr.com)
We note two interesting facts.
First, despite the fact that everyone knows Burroughs mainly for the supply of their mainframes (as the golden standard of secure architecture) for the US Federal Reserve, they also had military orders (although much less than IBM and Sperry, that during the Second World War they failed to establish contacts with the government).
And besides, their cars were very, very fond of universities. You can even say - they adored it, all over the world: in Britain, France, Germany, Japan, Canada, Australia, Finland and even New Zealand, more than a hundred Burroughs mainframes of different lines were installed. Architecturally (and in terms of style) Burroughs was the Apple of the big computer.
Their machines were rugged and phenomenally reliable, expensive, powerful, came as an absolute kit with all pre-installed and configured software and software packages, the architecture was closed, different from anything on the market.
They were loved by intellectuals of all stripes because Burroughs (just like the Macintosh of the golden era) just plug and play. By the standards of the mainframes of those years, even as successful as the S / 360, it was incredibly cool.
And, of course, they differed in design, branded convenient terminals, original disc loading system and many other things. We also note that in its years it was, although not a supercomputer, but a powerful working machine that produced about 2 MFLOPS - several times more powerful than anything that the USSR had at that moment.
In general, universities deservedly loved them, so using Burroughs as a scientific supercomputer in the Union would be a completely justified decision. A separate bonus was hardware support for Algol, a language that was considered, firstly, the gold standard of higher education (especially in Europe), and secondly, extremely slow on any other architectures.
Algol (whose full support did not appear in purely domestic machines) was deservedly considered the standard of classical academic structured programming. Not overloaded with esoteric constructions like PL / I, not as anarchic as Pure C, many times more convenient than Fortran, much less mind-bending than LISP and (God forbid) Prolog.
Before the advent of the concept of OOP, nothing more perfect and more convenient was created, and Burroughs were the only machines on which it did not slow down.
Another fact deserves great attention.
KoCom categorically did not allow us to purchase advanced architectures, even the restrictions on powerful workstations of the 1980s were lifted only after the collapse of the USSR, we had to fight fiercely for CDC, CYBER was sold with a creak (as we already mentioned, the director of Control Data was already under investigation by Congress about anti-American activities), and several machines were installed with goals in the interests of the United States.
CYBER from the Hydrometeorological Center was given to us for help with data on the Arctic climate, and CYBER LIAN was given in exchange for a promise to jointly develop recursive computers.
As a result, by the way, they were sold in vain, the joint work did not work out.
The real author of the idea, Torgashov, was quickly pushed to hell by his bosses, as soon as fame and money from working with the Yankees loomed on the horizon. The Americans arrived, tried to get some gestures in development from the bosses, who had difficulty imagining how ordinary machines work, eventually spat on everything and left.
So the USSR lost another opportunity to enter the world market.
But fresh Burroughs are delivered to us without blinking an eye, neither CoCom nor Congress object, no complaints. This can only be justified, again, by the interests of big business.
They sold it to oil workers with a guarantee that they would obviously not give up their charm to the military, they themselves need it, but it is very beneficial for both sides to be friends with the Soviet oil industry.
We also note that they began to sell Burroughs to us just in the Brezhnev years, when the intensity of the Cold War decreased significantly, as we wrote in previous articles. At the same time, the cunning Yankees were in no hurry to pump up their opponents with purely military technologies (such as the most powerful CDC 6600 or Cray-1), but they did not mind supporting Soviet business.
The PhD in Business Administration dissertation by Peter Wolcott from the University of Arizona Soviet Advanced Technology: The Case of High-Performance Computing, published back in 1993, however, states that the B6700 was installed in Moscow in 1977 ( that is, all approvals and delivery took a total of 4 years!).
Most of the preliminary design work on the Elbrus was completed from 1970 to 1973, when Burtsev could see a living car only in the USA (unfortunately, there is no information when exactly he went there).
At this time, ITMiVT engineers had access only to general documentation on the B6700 - the instruction architecture and block diagrams of the machine. Wolcott writes that they received more detailed information in 1975-1976 (apparently, after the trip of Burtsev, who brought a bunch of papers), which led to some improvements and changes in the structure of Elbrus.
Finally, in 1977, the developers studied the Moscow Burroughs in detail, which led to another wave of upgrades, probably with this, including the continuous process of making changes to the documents already coming into production.
Because of this, we can guarantee that inspiration visited Burtsev, clearly under the influence, first of all, of the works of the British, with whom he could familiarize himself in the mid-1960s. And yes, in those days, the direction of tagging-descriptor machines was indeed considered “in theoretical terms, the most powerful”, that is, it was supported, as the most promising, by almost the entire academic computer science in Britain.
In this regard, work on Elbrus was in line with the most advanced research at that time, and it was not the fault of British academics that in the mid-1980s the world turned in a completely different direction.
We also note that, according to theoretical articles, the Burtsev team did not succeed in building a car, only familiarization with the documentation on the live Burroughs allowed them to fully figure out how this thing works.
Architecture Comparison
The entire line of Burroughs Large Systems Group was built on a single B5000 architecture. The designations of the machines were extremely extravagant. The last three digits indicated the generation of machines, and the first - the serial number in terms of power in the generation.
Thus, we had the 000 series available (the only representative is the ancestor of the B5000), then the numbers from 100 to 400 were not used (they went to Medium Systems and Small Systems), and the next series received the 500 index. It had three computers, divided by power - simpler (B5500), more complicated (B6500) and, in theory, the most powerful (B8500).
However, the B6500 has already stalled, and as a result, the series was stuck on the younger model. The next number 600 also dropped out (so as not to be confused with CDC), and so the B5700, B6700 and B7700 line appeared.
They differed in the amount of memory, the number of processors and other architecturally non-principal details. Finally, the last line was the 800th series of two models (B6800 and B7800) and the 900th of three (B5900, B6900 and B7900).
All code written for Large Systems is reentrant out of the box, and the system programmer does not have to make any additional efforts for this. To put it simply, the programmer simply wrote the code, not thinking at all that it could work in multi-user mode, the system took control of it.
There was no assembler, the system language was a superset of ALGOL - the ESPOL language (Executive Systems Problem Oriented Language), in which the OS kernel (MCP, Master Control Program) and all system software were written.
It was replaced by the more advanced NEWP (New Executive Programming Language) in the 700 series. Two more extensions were developed for efficient work with data - DCALGOL (data comms ALGOL) and DMALGOL (Data Management ALGOL), and a separate command line language WFL (Work Flow Language) appeared for efficient MCP management.
The Burroughs COBOL and Burroughs FORTRAN compilers were also written in ALGOL and carefully optimized to take into account all the nuances of the architecture, so the Large Systems versions of these languages were the fastest on the market.
The bit depth of large Burroughs machines was conventionally 48 bits (+3 tag bits). Programs consisted of special entities - 8-bit syllables, which could be a call to a name, value, or make up an operator, the length of which varied from 1 to 12 syllables (this was a significant innovation of the 500 series, the classic B5000 used fixed instructions of length 12 bits).
The ESPOL language itself had less than 200 statements, all of which fit into 8-bit syllables (including the powerful line editing operators and the like, without them there were only 120 instructions). If we remove operators reserved for the operating system, such as MVST and HALT, the set commonly used by user-level programmers would be less than 100. Some operators (such as Name Call and Value Call) could contain explicit address pairs, others used an advanced branching stack.
Burroughs did not have registers available to the programmer (for the machine, the top of the stack and the next one were interpreted as a pair of registers), respectively, there was no need for operators to work with them, and various suffixes / prefixes were also not needed to indicate options for performing operations between registers , since all operations were applied to the top of the stack. This made the code extremely dense and compact. Many operators were polymorphic and changed their work in accordance with the data types that were defined by tags.
For example, in the Large Systems instruction set, there is only one ADD statement. A typical modern assembler contains several addition operators for each data type, such as add.i, add.f, add.d, add.l for integers, floats, doubles, and longs. In Burroughs, the architecture only distinguishes between single and double precision numbers - integers are simply reals with exponent zero. If one or both operands have tag 2, double precision addition is performed, otherwise tag 0 indicates single precision. This means that code and data can never be incompatible.
Working with the stack in Burroughs is implemented very beautifully, we will not bore readers with details, just take our word for it.
We only note that arithmetic operations took one syllable, stack operations (NAMC and VALC) took two, static branches (BRUN, BRFL and BRTR) took three, and long literals (for example, LT48) took five. As a result, the code was much denser (more precisely, it had more entropy) than in the modern RISC architecture. Increasing the density reduced instruction cache misses and therefore improved performance.
From the system architecture, we note SMP - symmetrical multiprocessor up to 4 processors (this is in the 500 series, starting from the 800 series, SMP has been replaced by NUMA - Non-uniform memory access).
Burroughs were generally pioneers in the use of multiple processors connected by a high speed bus. The B7000 line could have up to eight processors, provided at least one of them was an I/O module. The B8500 was supposed to have 16 but was eventually cancelled.
Unlike Seymour Cray (and Lebedev and Melnikov), Burroughs engineers developed the ideas of a massively parallel architecture - connecting many relatively weak parallel processors with a common memory, rather than using one super-powerful vector one.
As shown story This approach ended up being the best.
In addition, Large Systems were the first stack machines on the market, and their ideas later formed the basis of the Forth language and the HP 3000 computers. saguaro stack (this is such a cactus, so they call a stack with branches). All data was stored on the stack, with the exception of arrays (which could include both strings and objects), pages were allocated for them in virtual memory (the first commercial implementation of this technology, ahead of S / 360).
Another well-known aspect of the Large Systems architecture was the use of tags. This concept originally appeared in the B5000 in order to increase security (where the tag simply separated the code and data, like the modern NX bit), starting from the 500th series, the role of tags was significantly expanded. 3 bits instead of 1 were allocated for them, so there were 8 tag options in total. Some of them are: SCW (Software Control Word), RCW (Return Control Word), PCW (Program Control Word) and so on. The beauty of the idea was that bit 48 was read-only, so the odd tags denoted control words that could not be changed by the user.
The stack is very good, but how to work with objects that do not fit into it because of their structure, for example, strings? After all, we need hardware support for working with arrays.
Very simply, Large Systems uses descriptors for this. Descriptors, as the name suggests, describe the storage areas of structures, as well as I/O requests and results. Each descriptor contains a field indicating its type, address, length, and whether data is stored in the store. Naturally, they are marked with their own tag. The architecture of Burroughs descriptors is also very interesting, but we will not go into details here, we only note that virtual memory was implemented through them.
The difference between Burroughs and most other architectures is that they use paged virtual memory, which means that pages are paged out in fixed-sized chunks, regardless of the structure of the information in them. The B5000 virtual memory works with segments of different sizes, which are described by descriptors.
In ALGOL, array boundaries are completely dynamic (in this sense, Pascal with its static arrays is much more primitive, although this is fixed in the Burroughs Pascal version!), and in Large Systems, an array is allocated not by hand when it is declared, but automatically when it is accessed.
As a result, low-level memory allocation system calls, such as the legendary malloc in C, are no longer needed. This removes a huge layer of all kinds of shots in the foot for which C is so famous, and saves the system programmer from a bunch of complex and dreary routine. In fact, Large Systems are machines that support garbage collection a la JAVA, and in hardware!
Ironically, many users of Burroughs, who switched to it in the 1970s and 1980s and ported their (seemingly correct!) programs from the C language, found a lot of errors in them related to buffer overruns.
The problem of physical restrictions on the length of the descriptor, which did not allow addressing more than 1 MB of memory directly, was elegantly solved in the late 1970s with the advent of the ASD (Advanced Segment Descriptors) mechanism, which made it possible to allocate terabytes of RAM (in personal computers, this appeared only in the mid-2000s - X).
In addition, the so-called. p-bit interrupts, meaning that a block of virtual memory has been allocated, can be used in Burroughs for performance analysis. For example, this way you can notice that the procedure that allocates an array is constantly called. Accessing virtual memory drastically reduces performance, which is why modern computers start to work faster if you plug in another RAM chip.
In Burroughs machines, analyzing p-bit interrupts allowed us to find a systemic problem in the software and better balance the load, which is important for mainframes running 24x7 all year round. In the case of large machines, saving even a couple of minutes of time per day turned into a good final increase in productivity.
Finally, tags, like tags, were responsible for a significant increase in code security. One of the best tools a hacker has to compromise modern operating systems is a classic buffer overflow. The C language, in particular, uses the most primitive and error-prone way of marking the end of lines, using the null byte as an end-of-line signaler in the data stream itself (in general, such slovenliness distinguishes many things created, one might say, in an academic style, that is, smart people who do not have, however, special qualifications in the field of development).
In Burroughs, pointers are implemented as inodes. During indexing, they are checked by hardware at every increment/decrement to avoid block boundary overruns. During any read or copy, both the source and target blocks are controlled by read-only descriptors in order to maintain data integrity.
As a result, a significant class of attacks becomes impossible in principle, and many errors in software can be caught even at the compilation stage.
It's no wonder that Burroughs is so beloved by the universities. In the 1960s-1980s, qualified programmers, as a rule, worked in large corporations, scientists wrote software for themselves, as a result, Large Systems made their work tremendously easier, making it impossible to fundamentally screw up in any program.
Burroughs has influenced a huge number of technologies.
As we said, the HP 3000 line, and also their legendary calculators still in use today, were inspired by the Large Systems stack. The fault-tolerant servers of Tandem Computers also carried the imprint of this engineering masterpiece. In addition to Forth, the ideas of Burroughs significantly influenced Smalltalk, the father of all OOP, and, of course, the architecture of the JAVA virtual machine.
Why did such great machines die out?
Well, firstly, they did not die out immediately, the classic real Burroughs tag-descriptor architecture continued continuously in the UNISYS mainframe line until 2010 and only then lost ground to servers on the banal Intel Xeon (which even IBM is hellishly hard to compete with). The displacement occurred for one banal reason, which killed all other exotic cars of the 1980s.
In the 1990s, general-purpose processors like the DEC Alpha and the Intel Pentium Pro were pumped up to such tremendous performance that a lot of elaborate architectural tricks became unnecessary. SPARCserver-1000E on a pair of 90 MHz SuperSPARC-II beat Elbrus of all options like a god turtle.
The second reason Burroughs went down was the same problems that nearly killed Apple in the 1980s, exacerbated by the scale of the mainframe business. Their machines were so complex that they were extremely expensive and time consuming to develop, so they basically made only slightly improved versions of the same architecture throughout the 1970s. As soon as Burroughs tried to move somewhere else (as in the case of the B6500 or B8500), the project began to slip, absorb money at the speed of a black hole, and eventually was canceled (like the failed Apple III and Lisa).
Mainframe scale meant that Burroughs sold computers for millions of dollars with insanely expensive maintenance. For example, the B8500 was supposed to have 16 processors, but the estimated cost of a configuration even with three was more than $14 million, and therefore the contract for its supply was terminated.
In addition to the phenomenal cost of the machines themselves, the company's older mainframes demanded a huge amount of money for support. The annual package of maintenance, service and all licenses for all software, in the case of the top model B7800, cost about $1 million a year, not everyone could afford such a luxury!
I wonder if the Soviet oilmen bought a full service or did they repair their Burroughs themselves, with a strong word and a sledgehammer?
So the Burroughs business was always limping, lacking the scale and strength of IBM. They could not make cheap cars due to the complexity of development, and buyers for expensive cars, given the active battle with competitors, were not enough to increase profits and the opportunity to invest extra money in development and reduce prices, making cars more competitive.
Sperry UNIVAC suffered the same problems, eventually in 1986 the two corporations merged to survive to form UNISYS, which has been producing mainframes ever since.
In addition to the architectures mentioned, Burtsev really used the experience of 5E26 and 5E92b in terms of hardware error control. Both of these computers were capable of hardware detection and correction of any one-bit errors, and in the Elbrus project this principle was taken to new heights.
So, we are waiting for the answer to the most fascinating question - was Elbrus El Burrows?
As we remember, Ailif abandoned the classical von Neumann model, the machine as a linear storage of instructions and data. The saguaro stack at Burroughs was a tree structure reflecting the execution of parallel code and the hierarchy of processes in a multi-user multiprogramming environment. Note, by the way, that ALGOL, with its block hierarchical structure, fits perfectly on the stack, which is why its implementation in Large Systems was so successful.
This philosophy of integrated design was non-trivially promoted by Elbrus system architects, who raised it to a new level. In particular, instead of several specialized languages, a group of developers from ITMiVT created one universal, Algol-like El-76.
The architectural novelties did not end there.
A direct comparison of the machines is given in the table below, the old B6700 as a whole looks good against the background of a computer 17 years younger.
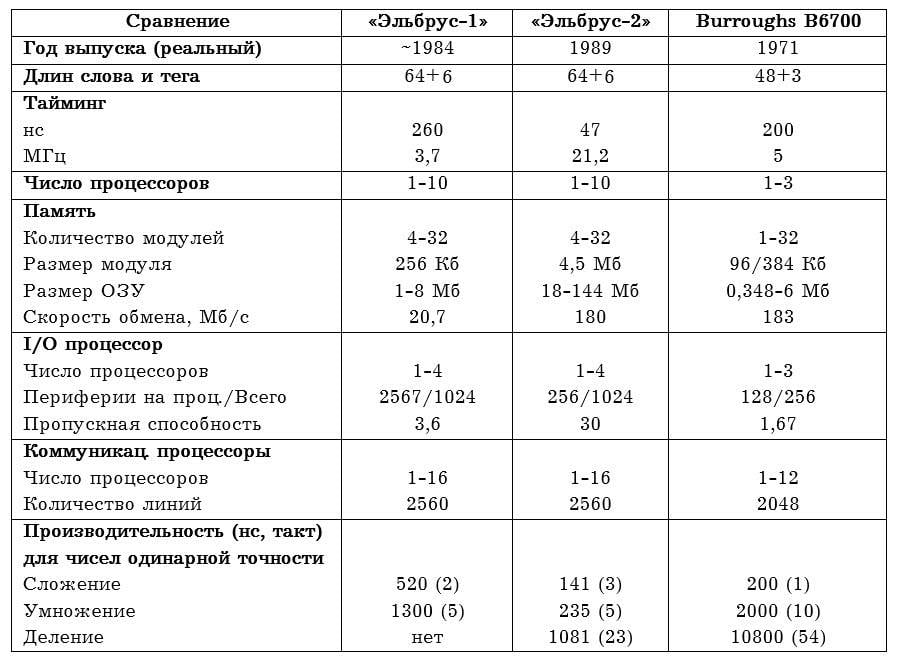
From the interesting - unlike the B6700, Elbrus was monstrously huge.
The first version occupied 300 sq. m in a single-processor and 1 sq. m in a 270-processor configuration, and the second - respectively 10 and an incredible 420 sq. m, thus taking away the laurels of the largest computer in history from the IBM AN / FSQ-2 Project SAGE itself, which, being a tube one, occupied 260 sq. m.

To understand the scale. Wembley Stadium. Approximately so much was occupied by the Elbrus multi-machine complex for the A-135 missile defense system.
The CPU of both machines is based on a CISC stack architecture with reverse Polish notation. The code of a compiled program consists of a set of segments. A segment usually corresponds to one procedure or block in a program. When program execution begins, two memory locations are allocated: one for the stack and one for the segment dictionary, which is used to refer to multiple program segments in RAM. Memory areas for code segments and arrays are allocated by the OS on demand.
Descriptors in both machines are responsible for code reentrancy by organizing automatic memory sharing between executing threads. Code and data are strictly separated by tags, descriptors allow you to run identical code on different data sets for different users, with a guarantee of their protection.
Both computers even use identical special-purpose registers (for example, each machine has base-of-stack, stack limit, and top-of-stack registers) and stack management instructions.
Burroughs and Elbrus have a very similar philosophy, but differ greatly in the design of the processor itself.
The B6700 processor consists of a 48-bit adder, an address processing unit, seven function controllers (program, arithmetic, string, stack adjust, interrupt, transfer, and memory) and a set of registers. The latter include 4 51-bit data registers (two top stack elements, current value, intermediate value) and 48 20-bit instruction registers (32 display registers responsible for storing entry points to currently executing procedures, and 8 base registers each). addresses and index registers).
The most interesting thing in the processor was an extremely tricky block, the so-called. controllers of a family of operations (in the amount of 10 pieces), which, from the available functional blocks, built a computational pipeline for each command. This allowed to significantly reduce the cost of transistors.
The controller passes the decoded instruction to the Current Program Instruction Word register and selects the appropriate operator family controller. The key feature is that the instructions are executed strictly sequentially in the order dictated by the compiler. Arithmetic instructions cannot overlap because there is only one adder in the CPU.
This was the main difference between the Elbrus processor. Babayan proudly beat his chest with his fist and declared "the world's first superscalar in Elbrus" (which he had nothing to do with the development at all), but in practice, Burtsev carefully studied the architecture of the great CDC 6600 in order to learn the secrets of interaction between groups of functional blocks in parallel conveyors.
From the CDC 6600, Elbrus borrowed the architecture of multiple functional blocks (10 in total): adder, multiplier, divider, logical block, BCD encoding conversion block, operand call block, operand write block, string processing block, subroutine execution block and indexing block.
There is some functional overlap between these blocks and the B6700 controllers, but there are also important differences, for example, arithmetic in Elbrus has 4 independent groups instead of one.
Multiple ALUs have already been used in other machines, but never in the world - on a stack processor. Naturally, this was not done because of the great stupidity of Western developers. The stack, by definition, assumes zero addressing - all the necessary operands must lie on top. Obviously, in the absence of traditional addresses, only one operation per cycle can correctly address the top - this basically excludes the operation of parallel blocks.
Burtsev's group had to monstrously pervert in order to get around this limitation.
In fact, the B6700 stack processor in the Elbrus version has ceased to be a stack processor at all! Miracles do not happen and a hedgehog does not interbreed with a snake, so the internal architecture, invisible to the programmer, had to be made a classic register one. The controller receives and decodes the command as usual, and then converts it to internal register format. B6700 interpreted only 2 top elements of the stack as internal registers, Elbrus - 32 elements! In fact, there is only one name left from the stack.
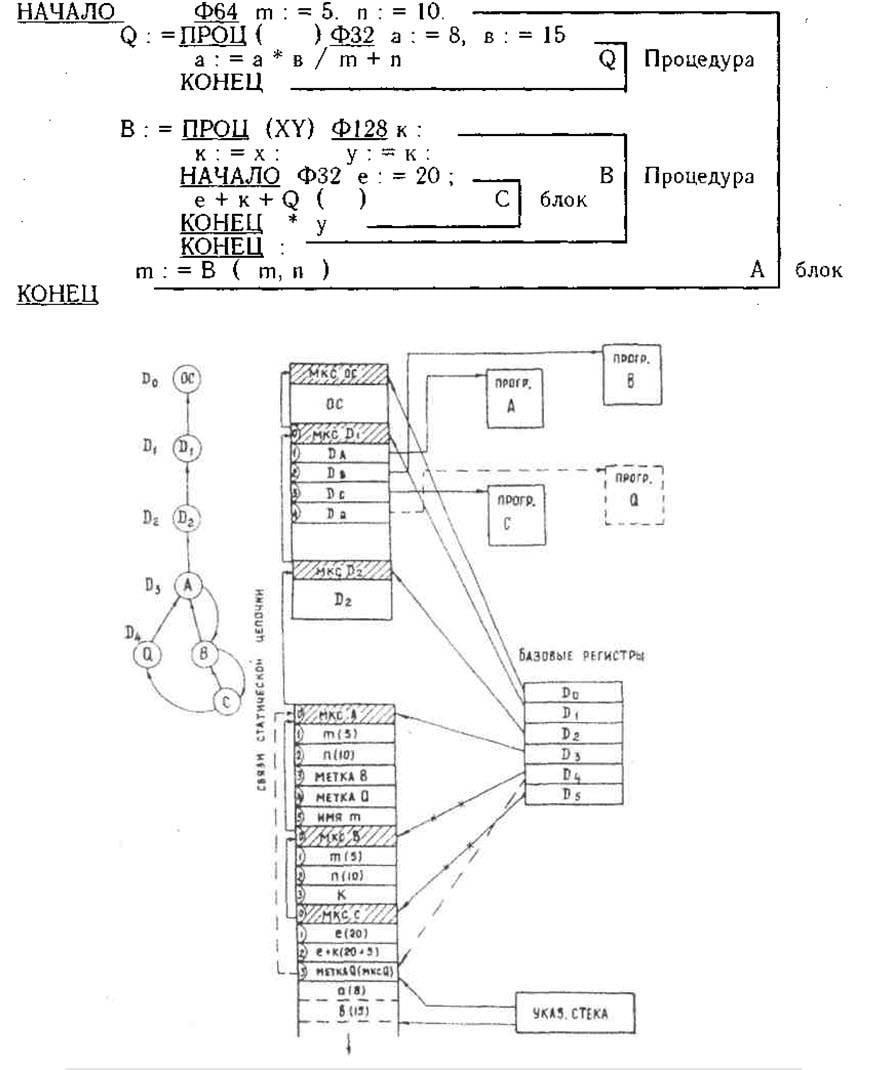
The state of the Elbrus pseudostack at the moment of transition to procedure Q. From the article by Burtsev “Principles of building multiprocessor computing systems Elbrus”.
Naturally, this would be completely useless if the CU could not load all functional devices in parallel. This is how the mechanism of speculative execution was developed, which is also absolutely original.
Elbrus instructions can be passed to function blocks before all required operands are available, once loaded they will simply wait for data. In fact, the execution occurs according to the principle of the dataflow architecture, the exact order of execution depends on the order in which the operands become available.
What did they achieve in the end?
Well, the reaction of a modern programmer to such wild decisions is obvious:
I remember working with arrays killed me. Switching to supervisor mode to allocate an array - is that normal? Is it normal for the execution pipeline to know about arrays? Working with arrays through a descriptor - is that efficient? Type out of bounds is faster to check, right? It's scary to imagine how this horror will fall on the equipment at all. However, then there was a different layout with latency and speed of memory and other components, not at all the same as now. She could justify such bold moves, but such designs do not live, in any way. In fact, they didn't survive...
Theoretically, the developers of pure tag machines started from the fact that in the mid-1970s there were still no architectures and compilers capable of at least some automatic code parallelization, as a result of which, most of the multiprocessor systems could not be efficiently loaded completely, and the execution units were often idle. The way out of this impasse was the superscalar architecture or the notorious VLIW machines, but they were still far away (although the first superscalar processor was used by the same Cray in the CDC6600 back in 1965, there was no smell of mass production here yet). And so the idea was born to facilitate the work of a programmer by transferring the architecture to a Java language. However, it is worth noting that it is not easy to make a good superscalar on a stack architecture - it is much easier to make for RISC instruction systems. Let's see what kind of superscalar is in Elbrus-2: “The rate of command processing in the control device can vary from two commands for 1 cycle to one command for 3 cycles. The most common combinations of commands are processed at the maximum rate: read the value and the arithmetic command; load address and take array element; download the address and write it down."
As a result, we have what we have - a superscalar for two instructions per clock cycle, and the most primitive instructions. There is nothing to be proud of here, it’s good that at least they know how to combine data reading with arithmetic (and only when it gets into the cache).
Theoretically, the developers of pure tag machines started from the fact that in the mid-1970s there were still no architectures and compilers capable of at least some automatic code parallelization, as a result of which, most of the multiprocessor systems could not be efficiently loaded completely, and the execution units were often idle. The way out of this impasse was the superscalar architecture or the notorious VLIW machines, but they were still far away (although the first superscalar processor was used by the same Cray in the CDC6600 back in 1965, there was no smell of mass production here yet). And so the idea was born to facilitate the work of a programmer by transferring the architecture to a Java language. However, it is worth noting that it is not easy to make a good superscalar on a stack architecture - it is much easier to make for RISC instruction systems. Let's see what kind of superscalar is in Elbrus-2: “The rate of command processing in the control device can vary from two commands for 1 cycle to one command for 3 cycles. The most common combinations of commands are processed at the maximum rate: read the value and the arithmetic command; load address and take array element; download the address and write it down."
As a result, we have what we have - a superscalar for two instructions per clock cycle, and the most primitive instructions. There is nothing to be proud of here, it’s good that at least they know how to combine data reading with arithmetic (and only when it gets into the cache).
In principle, the USSR in this sense defeated itself, Burroughs machines, as already mentioned, did not do without such frills not because of the stupidity of their architects. They wanted to do a pure stack architecture and they did it right.
In Elbrus, one name remained from the elegant simplicity of the stack, while the machine became an order of magnitude more expensive and more complicated (what hell it was to debug the Elbrus processor, the person who did this will tell us later), but in performance it still didn’t really win - received a mixture of shortcomings of both classes of machines.
In general, this is the case when it would be better to steal the idea as it is, without trying to Sovietize it, that is, to expand and deepen it.
What was there about arrays?
Burtsev put in his 5 kopecks here too.
In the Burroughs B6700, all array elements are accessed indirectly, by indexing through the array descriptor. This takes an extra cycle. In Elbrus, they decided to remove this cycle and added a hardware block for prefetching array elements to the local cache. The index block contains associative memory, which stores the address of the current element along with the step in memory.
As a result, the handle is only needed to pull out the first element of the array; everyone else can be contacted directly. Associative memory can store information about six arrays, and calculating the address of an element in a loop takes only one cycle, array elements for even 5 iterations of the loop can be extracted in advance.
With this innovation, the developers have achieved a significant acceleration of vector operations in Elbrus compared to the B6700, which was built as a purely scalar machine.
The memory architecture has also undergone significant changes.
The B6700 had no cache, only a local set of special purpose registers. In Elbrus, the cache consists of four separate sections: an instruction buffer (512 words) for storing instructions executed by the program; a stack buffer (256 words) for storing the most active (topmost) part of the stack, which is otherwise stored in main memory; array buffer (256 words) for storing array elements that are processed in cycles; associative memory for global data (1 words) for data other than those stored in other buffers. This includes program global variables, handles, and procedure local data that do not fit in the stack buffer.
This cache organization made it possible to effectively include a relatively large number of processors in a shared memory configuration.
What is the problem with screwing the cache to a multiprocessor system?
The fact is that each processor can have its own local copy of the data, but if we want to force the processors to process one task in parallel, then we must make sure that the contents of the caches are identical.
Such a check is called maintaining cache coherence and requires numerous RAM accesses, which terribly slows down the system and kills the whole idea. That is why the number of processors in the SMP architecture - symmetrical multiprocessorism, rarely exceeds 4 pieces (even now 4 is the classic maximum number of sockets in a server motherboard).
The IBM 3033 (1978) dual-processor mainframe used a simple store-through design in which data changed in cache is immediately updated in RAM.
The IBM 3084 (1982, 4 processors) used a more advanced coherence scheme where data transfer to RAM could be delayed until cache entries were overwritten or until another processor accessed the corresponding data entries in main memory.
That is why the 3-processor B6700 did without a cache - its processors were already too fancy.
Cache coherence in Elbrus was maintained by using the concept of a critical section in a program, which is well known to OS architects. Parts of the program that access resources (data, files, peripherals) shared by several processors set up a special semaphore at the time of access, which means entering the critical section, after which the resource was blocked for all other processors. After leaving it, the resource was unlocked again.
Given that critical sections accounted for (at least according to the developer) about 1% of the average program, 99% of the time cache sharing did not incur the overhead of maintaining coherence. Instructions in an instruction buffer are, by definition, static, so their copies in multiple caches remain identical. This is one of the reasons why Elbrus supported up to 10 processors.
In general, its architecture is an example of a very early use of a segmented cache, a similar principle (stack buffer, instruction buffer and associative memory buffer) was already implemented in the B7700, but it came out in 1976, when most of the work on creating the Elbrus architecture was completed.
Thus, Elbrus deservedly receives the title of one of the world's first general-purpose systems with memory shared by 10 processors.
Technically (taking into account the fact that Elbrus-2 worked normally only in 1989), the first released supercomputer of this type was the Sequent Balance 8000 with 12 National Semiconductor NS32032 processors (1984; the Balance 1986 version with 21000 processors was released in 30), but the idea itself came to the Burtsev group definitely ten years earlier.
The Elbrus memory model was extremely effective.
For example, the execution of a simple program in the style of adding several numbers with reassignment required in the case of S / 360 from 620 memory accesses (if written in ALGOL) to 46 (if written in assembler), 396 and 54 in the case of BESM-6 and only 23 in " Elbrus".
Like Burroughs machines, Elbrus uses tags, but their use has been expanded many times over.
In their zeal to transfer as much control as possible to the hardware, Burtsev's group doubled the tag length to 6 bits. As a result, the machine was able to distinguish between half/single/double precision operands, integers/real numbers, empty/full words, labels (including such specialized things as "privileged label without external interrupt block" and "label without address information recorder"), semaphores, control words, and others.
One of the main goals of creating labels was to simplify programming. If function blocks could distinguish between real and integer operands, they could be designed to adapt to computations on either, and there would be no need for separate scalar and real blocks.
In fact, Elbrus implemented dynamic typing at a level comparable to modern OOP, and in hardware.
Another purpose of tags was to detect errors, such as an attempt to perform an arithmetic operation on an instruction, tags could also be used to protect memory, restrict the writing of certain data, etc.
In the field of tags, Elbrus has taken the ideas of the base machine and the B6700 to a new level of sophistication.
All this made it possible to achieve what the Burroughs architects did not achieve. As we remember, they needed separate ALGOL extensions for writing OS code and subsequent system management. The developers of "Elbrus" abandoned this idea and created a single complete universal language "El-76", in which everything could be written.
To write an entire OS in a high-level language (including the code responsible for the lowest-level internal things, such as memory allocation and process switching), requires very high-level special hardware. For example, process switching in the Elbrus OS was implemented as a sequence of assignment operators that perform well-defined actions on special hardware registers.
The design of the RAM in both machines is extremely similar, although Elbrus (especially in the second version) contains much more memory.
RAM "Elbrus" is organized hierarchically, the memory section (1 cabinet) consists of 4 modules, each module consists of 32 blocks of 16 words. Alternation is possible at several levels: between sections, between modules within a section, and within individual modules. Up to four words can be read from each memory module in one cycle. The maximum memory bandwidth is 450 MB/s, although the maximum data transfer rate with each processor is 180 MB/s.
The memory management schemes in the B6700 and Elbrus are generally very similar. Memory is organized into variable-length segments that represent logical sections of a program as defined by the compiler. According to the logical division of the program, segments can have different levels of protection and be shared between processes.
In the B6700, segments moved between the main and virtual storage as a whole. Arrays were the exception. They could be stored in the main memory in groups of 256 words each, bounded on both sides by linking words.
In Elbrus, code segments are treated differently than data segments and arrays. The code is processed in the same way as in the B6700, and the data and arrays are organized into pages of 512 words each.
The Elbrus approach is more efficient here and allows faster swapping.
In addition, Elbrus uses a more modern type of virtual memory.
In Burroughs computers, addressing was limited to 20 bits, or 220 words, the maximum physical memory in the B6700/7700. The presence of segments in main memory was indicated by a special bit in their descriptor, which remained in RAM during the execution of the process. There was no concept of a true virtual memory space that was larger than the total amount of physical memory; descriptors contained only physical addresses.
Elbrus machines used a similar 20-bit addressing scheme for program segments, but 32-bit addressing was used for data segments and arrays of constants. This provided a virtual memory space of 232 bytes (4 gigabytes). These segments were moved between virtual and physical memory using a paging mechanism that used the paging tables stored in the paging memory associative block to convert between virtual and physical addresses. Virtual addresses consist of a page number and an offset within the page. This is actually a full-fledged modern implementation of virtual memory, the same as in IBM machines.
So what's our verdict?
Elbrus was definitely not a complete clone of Burroughs B6700 (and even B7700).
Moreover, he was not even his ideological clone, rather, his brother, because both the B6700 and Elbrus were inspired by the same source - Ailif's work on the base machine and the works of the University of Manchester, and the common ancestor of the B-series, the famous B5000 , was a development of the ideas embodied in Rice's car R1. In addition, Elbrus used the CDC 6600 as inspiration (where without it) and in terms of working with virtual memory - IBM S / 360 model 81.
In this regard, we, without a doubt, admit that the architecture of Elbrus itself was absolutely in the trend of world developments of the 1970s and was a worthy representative of them.
Moreover, in many aspects it was much more advanced than the B6700/7700.
Perhaps only attempts to achieve superscalarism can be recognized as a really unsuccessful decision, which failed both in terms of architecture (a superscalar for 2–3 operations, as already mentioned, is not worth the candle), and practical (as a result, the already monstrously a complex processor became even more complex, occupying a huge T-shaped cabinet and almost impossible to debug, which is why it was fussed with for so many years) points of view.
Unfortunately, in order to bypass such moments, one must have colossal experience and intuition, developed over the years of work with the world's best examples of architecture, which, of course, was not in the Union.
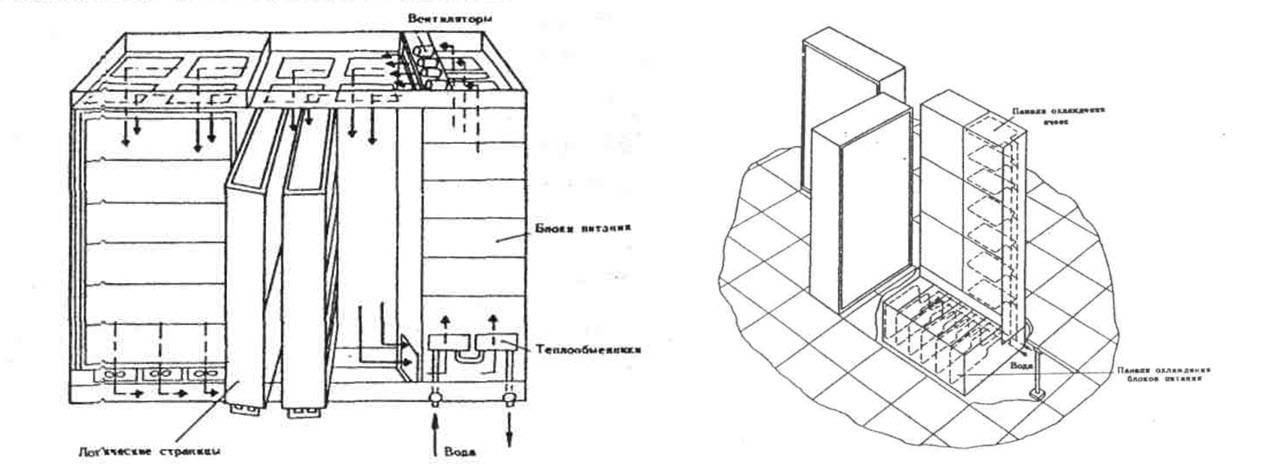
Typical cabinet "Elbrus-1" and CPU "Elbrus-2" from Burtsev's article "Parallelism of computing processes and the development of supercomputer architecture. MVC "Elbrus".
Naturally, one should not talk about any originality of Elbrus - in fact, it was just a compilation of various technical solutions, significantly improved in some aspects.
But from this point of view, the B5000 was also a highly advanced version of the R1, as we have already said.
There is also no question about the relevance of such an architecture now - the 1970s are long gone, the history of IT has turned in a completely different direction and has been going there for 40 years.
So, on paper, "Elbrus" by the standards of 1970 was, without underestimation, a masterpiece, quite comparable to the best Western cars. And here is its implementation...
However, this is a topic for the next article.
To be continued ...
Information